5 Pipes in R
Now here I would like to introduce you with the concept of pipes in R. There are two types of pipes used-
-
|>is native pipe of R. It was introduced in R version 4.1 -
%>%pipe introduced inmagrittrpackage5, now part oftidyversewhich we will use extensively in our data analysis tasks.

Figure 5.1: Magrittr, the R package, is named after the surrealist painter Rene’ Magritte. His painting was self captioned, ‘This is not a pipe.’
Actually %>% is predecessor to native R’s pipe |>. The pipes are powerful tools for clearly expressing a sequence of operations that transform an object, without the need of actually creating that object in each step. Let us understand this concept with the following example. Suppose, we have to three functions say FIRST , SECOND and THIRD to an object OBJ in sequence. So the order of operations would either be like-
THIRD(SECOND(FIRST(OBJ)))or with creating intermediate objects, when instead we actually do not need those intermediate objects.
OBJ1 <- FIRST(OBJ)
OBJ2 <- SECOND(OBJ1)
OBJ3 <- THIRD(OBJ2)Here actually we do not require OBJ1 and OBJ2. So in these cases we either have to compromise with the readability of code i.e. inside out or have to create unwanted objects. Pipes actually mitigate both these issues simultaneously. With pipes we can write above operations as either of these -
OBJ1 |> FIRST() |> SECOND() |> THIRD()
OBJ1 %>% FIRST() %>% SECOND() %>% THIRD()A diagrammatic representation is given in figure 5.2.
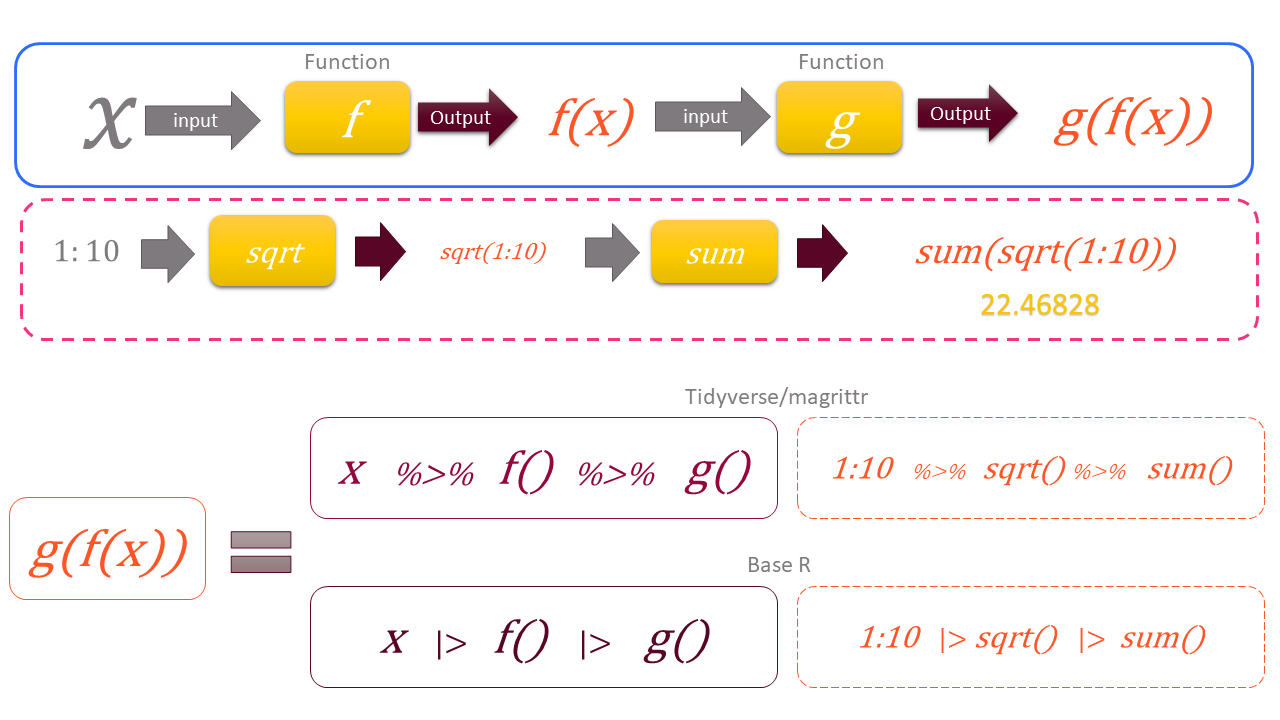
Figure 5.2: A diagrammtic illustation of Pipe concept in base R and tidyverse
Now two questions may arise here-
- What if there are multiple arguments to be passed in any of the operations?
- Is there any difference between the two pipes? If yes, which is better OR what are the pros and cons of each?
To answer these questions, we will discuss both pipes separately.
Figure 5.3: Using pipes in R
5.1 Magrittr/Dplyr pipe %>%
Pipes usually pass result of previous operation silently into first argument of next/right expression. So data %>% filter(col == 'A') means filter(data, col=='A'). But there may be cases when result of previous (LHS) expression is required to be passed on second or other argument in RHS expression. A simple example may be of function lm, where data argument is second argument. In such cases we can make use special placeholder . as result of LHS specifically. In other words aforesaid filter example can be written with placeholder as data %>% filter(. , col == 'A'). Now using this placeholder we can use result of LHS wherever we want. See this example
##
## Call:
## lm(formula = Sepal.Length ~ Sepal.Width, data = .)
##
## Coefficients:
## (Intercept) Sepal.Width
## 6.5262 -0.2234Thus x %>% f(y) is equivalent to f(x, y) but x %>% f(y, .) is equivalent to f(y, x).
5.2 Base R pipe |> (Version 4.2.0 +)
R version 4.2.0 introduced concept of placeholder _ similar to dplyr/magrittr, but with a few differences.
- The argument where
_is to be used, must be named. Sof(y, z = x)can be written asx |> f(y, z= _).
##
## Call:
## lm(formula = Sepal.Length ~ Sepal.Width, data = iris)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.5561 -0.6333 -0.1120 0.5579 2.2226
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.5262 0.4789 13.63 <2e-16 ***
## Sepal.Width -0.2234 0.1551 -1.44 0.152
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8251 on 148 degrees of freedom
## Multiple R-squared: 0.01382, Adjusted R-squared: 0.007159
## F-statistic: 2.074 on 1 and 148 DF, p-value: 0.1519The requirement of named argument is not there in dplyr pipe. So essentially, iris %>% lm(Sepal.Length ~ Sepal.Width, .) will also work. But in base R iris |> lm(Sepal.Length ~ Sepal.Width, _) would not work and throw an error. Thus, in cases where the argument of placeholder is not named, we have to use anonymous function. See these-
# placeholder without named argument
iris |> lm(Sepal.Length ~ Sepal.Width, _)
# Correct way to use unnamed argument
iris |> {\(.x) lm(Sepal.Length ~ Sepal.Width, .x)}() |> summary()##
## Call:
## lm(formula = Sepal.Length ~ Sepal.Width, data = .x)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.5561 -0.6333 -0.1120 0.5579 2.2226
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 6.5262 0.4789 13.63 <2e-16 ***
## Sepal.Width -0.2234 0.1551 -1.44 0.152
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.8251 on 148 degrees of freedom
## Multiple R-squared: 0.01382, Adjusted R-squared: 0.007159
## F-statistic: 2.074 on 1 and 148 DF, p-value: 0.1519Type ?`|>` in console and see help page for more details.